
4D v16
Architecture de 4D Server
- 4D Server - Référence
-
- Introduction
-
- Présentation
- Architecture de 4D Server
 Architecture de 4D Server
Architecture de 4D Server
Avec son architecture client/serveur, 4D Server ne se contente pas de stocker et de gérer la base de données, mais fournit également des services aux clients. Ces services fonctionnent à travers le réseau par l'intermédiaire d'un système de requêtes et de réponses.
Pour rechercher un ensemble d'enregistrements, par exemple, un poste client envoie une requête au serveur. Dès réception de la requête, 4D Server exécute la recherche en local (c'est-à-dire sur le poste serveur) et, lorsqu'elle est terminée, en retourne le résultat (les enregistrements trouvés).
L'architecture de 4D Server est basée sur le modèle client/serveur. Depuis de nombreuses années, le modèle d'architecture client/serveur s'est imposé, face à son concurrent plus ancien, le partage de fichiers, comme le plus efficace pour les bases de données multi-utilisateurs.
Le type d'architecture client/serveur de 4D Server est comparable à celui qui est utilisé dans le monde de la mini-informatique. De plus, 4D Server apporte deux innovations importantes :
- Une interface intuitive et graphique, présente à tous les niveaux de la base,
- Une architecture intégrée, permettant d'accroître l'efficacité et la vitesse.
Avant l'apparition de l'architecture client/serveur, les systèmes multi-utilisateurs exploitaient le partage de fichiers comme modèle d'architecture réseau. Dans ce modèle, tous les utilisateurs partagent les mêmes données mais la gestion des données n'est pas contrôlée par un moteur de base de données central. Chaque poste client doit stocker une copie de la structure et du moteur de la base, tandis que le serveur n'est chargé que de la gestion du logiciel de partage de fichiers sur le réseau.
Dans le modèle du partage de fichiers, chaque station de travail effectue en local toutes les actions de modification sur les données. Cela a pour conséquence de créer un trafic réseau très important, car chaque requête nécessite de nombreuses communications à travers le réseau. Le schéma suivant présente un exemple de trafic réseau généré lorsqu'un utilisateur recherche chaque personne dont le nom est “Smith”.
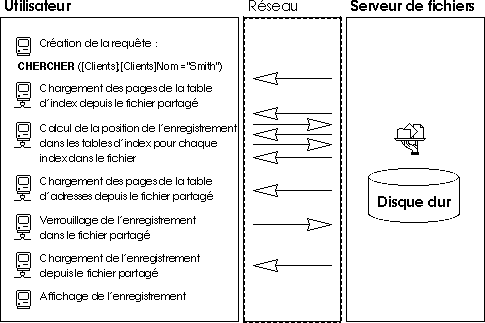
Autre inconvénient du modèle du partage de fichiers : l'impossibilité d'utiliser un cache mémoire pour conserver des enregistrements en mémoire. Si des enregistrements étaient conservés en mémoire, il pourrait exister différentes versions du même enregistrement stocké dans la mémoire cache, ce qui rendrait les données incohérentes. Par conséquent, chaque fois qu'un utilisateur accède à un enregistrement, celui-ci doit être téléchargé depuis le serveur de fichiers. Cela provoque un trafic réseau intense et augmente le temps d'accès aux données.
L'architecture client/serveur est largement répandue dans le monde de la mini-informatique, pour la gestion de bases de données volumineuses, grâce à son efficacité et à sa vitesse. Avec cette architecture, le travail est divisé entre les clients et le serveur de manière à augmenter les performances.
Le serveur contient le moteur central de la base, qui stocke et gère les données. Le moteur de la base est le seul logiciel ayant accès aux données stockées sur le disque. Lorsqu'un client envoie une requête au serveur, le serveur retourne le résultat. Le résultat peut être de toute nature, depuis un simple enregistrement à modifier jusqu'à une liste triée d'enregistrements.
En général, la plupart des architectures client/serveur sont appelées architectures hétérogènes car les applications frontales exécutées sur les postes clients et le moteur de base de données exécuté sur le serveur sont deux produits différents. Dans cette situation, un pilote de base de données est requis pour servir de traducteur entre les clients et le serveur.
Par exemple, pour rechercher un enregistrement, un client envoie une requête au serveur. Comme la base est stockée sur le serveur, celui-ci exécute la commande en local et expédie le résultat au client. Le schéma suivant présente un exemple de trafic réseau généré lorsqu'un utilisateur recherche chaque personne dont le nom est “Smith” et affiche le premier enregistrement trouvé.
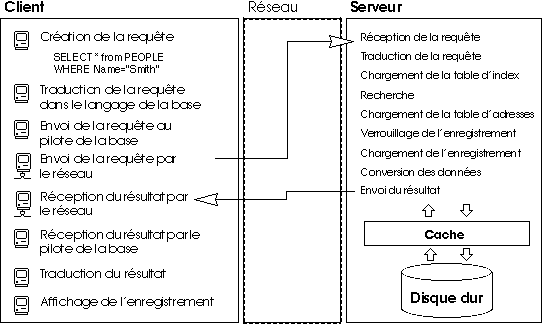
Cet exemple illustre deux différences majeures entre le partage de fichiers et l'architecture client/serveur :
- L'architecture client/serveur autorise l'utilisation d'un cache : Comme le moteur est le seul logiciel qui dispose de l'accès physique aux données, le serveur peut utiliser un cache qui conserve en mémoire les enregistrements modifiés jusqu'à ce qu'ils soient écrits sur le disque. Comme les données sont envoyées depuis un site central, les postes clients sont assurés de toujours recevoir la dernière version d'un enregistrement. En plus du contrôle de l'intégrité des données qu'il procure, le mécanisme de cache central accélère les opérations de base de données en remplaçant les accès disque par des accès mémoire. Avec le partage de fichiers, tous les accès sont des accès disque.
- Les opérations de base de données de bas niveau sont effectuées sur le serveur : L'architecture client/serveur permet une augmentation importante de la vitesse d'exécution, car les manipulations de bas niveau sur la base de données, telles que l'examen des tables d'index et d'adresses, sont exécutées localement sur le serveur, à la vitesse de la machine. Avec le partage de fichiers, les mêmes opérations sont ralenties par les transferts sur le réseau et les limites du poste client.
Dans la plupart des architectures client/serveur, l'application cliente et l'application serveur sont deux produits séparés, nécessitant une couche de communication pour pouvoir se comprendre entre eux. Avec 4D Server, l'architecture client/serveur est entièrement intégrée. 4D Server et 4D sont deux applications qui partagent la même structure et communiquent directement.
Comme 4D Server et 4D parlent la même langue, il est inutile de traduire les requêtes. La division du travail entre le client et le serveur est transparente et est gérée automatiquement par 4D Server.
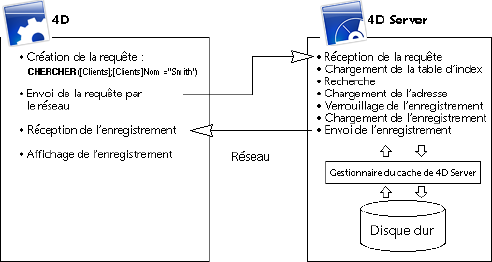
La division du travail est organisée de telle manière qu'à une requête est associée une réponse. Comme vous pouvez le constater dans le schéma ci-dessus, le client est chargé de traiter les tâches suivantes :
- Requêtes : Le client 4D envoie des requêtes à 4D Server. Ces requêtes peuvent être construites à l'aide des éditeurs intégrés, tels que l'éditeur de recherches et l'éditeur de tris, à l'aide du langage intégré de 4D ou via le SQL. 4D dispose d'éditeurs dans lesquels les méthodes peuvent être créées et modifiées. Il gère également les éléments des méthodes telles que les variables et les tableaux.
- Réception des réponses : Le client 4D reçoit des réponses de 4D Server et en informe l'utilisateur par l'intermédiaire de l'interface utilisateur (des enregistrements différents sont affichés dans un formulaire, etc.). Par exemple, si le client recherche tous les enregistrements dont le nom est “Smith”, 4D reçoit les enregistrements de 4D Server et les affiche dans un formulaire.
Le serveur est chargé de traiter les tâches suivantes :
- Gestion des accès : 4D Server gère toutes les connexions simultanées et les process créés par les clients. Cette gestion tire parti de l'architecture multi-tâche de 4D Server.
- Objets de structure et de données : 4D Server stocke et gère tous les objets de structure et de données, y compris les champs, les enregistrements, les formulaires, les méthodes, les barres de menus et les listes.
- Cache : 4D Server gère le cache contenant les enregistrements ainsi que des objets de données créés par les postes clients, tels que les sélections et les ensembles.
- Opérations de base de données de bas niveau : 4D Server exécute les opérations de base de données dites "de bas niveau", telles que les recherches et les tris, qui impliquent l'utilisation des tables d'index et d'adresses.
Cette division du travail est extrêmement efficace grâce à l'intégration unique 4D Server et 4D. L'intégration de l'architecture de 4D Server est présente à chaque niveau :
- Au niveau de la requête : Lorsque 4D envoie à 4D Server une requête, telle qu'une recherche ou un tri, 4D envoie une description de l'opération de recherche ou de tri en utilisant la même structure interne que 4D Server.
- Au niveau de la structure et des données : Lorsque 4D et 4D Server échangent un objet de structure ou de données, les deux applications utilisent le même format interne. Lorsque 4D a besoin d'un enregistrement, par exemple, 4D Server envoie directement les données dans le format où elles sont stockées sur le disque ou dans le cache mémoire. De la même manière, lorsque 4D met à jour un enregistrement et envoie les données à 4D Server, celui-ci les stocke directement dans le cache exactement telles qu'il les a reçues.
- Au niveau de l'interface utilisateur : Lorsque 4D affiche une liste d'enregistrements, le formulaire utilisé joue un rôle dans l'architecture client/serveur. Par exemple, la fenêtre suivante montre le résultat d'une requête dans la table [Sociétés].
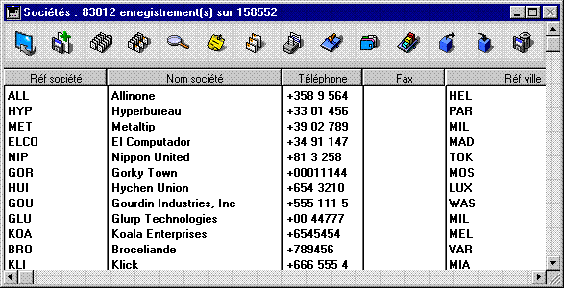
Comme la taille de la fenêtre ne permet d'afficher que douze enregistrements et cinq champs à la fois, 4D Server envoie exactement douze enregistrements. Au lieu d'envoyer la totalité des enregistrements, 4D Server n'envoie que le nombre d'enregistrements et de champs pouvant être affichés dans la fenêtre. Si l'utilisateur fait défiler les enregistrements dans le formulaire, 4D Server envoie les enregistrements et les champs supplémentaires à mesure qu'ils apparaissent dans la fenêtre. Cette optimisation réduit le trafic réseau, car les enregistrements et les champs ne sont envoyés que lorsque c'est nécessaire.

Produit : 4D
Thème : Introduction
4D Server - Référence ( 4D v16)






