
4D v16.3
コンパイルの診断ツール
- デザインリファレンス
-
- コンパイル
-
- 概要
- コンパイラーウィンドウ
- コンパイル設定
- コンパイルの診断ツール
 コンパイルの診断ツール
コンパイルの診断ツール
データベースの分析や訂正を行うために、3種類のツールが用意されています:
- 実際の解析用ツールはシンボルファイルにより提供されます。このテーブルを使用して、変数を素早く見つけることができます。このツールは、コンパイラーにより報告されたエラーメッセージを解析する上で非常に役立ちます。
- 訂正用ツールはエラーファイルにより提供され、このファイルはテキストファイルとして使用することができます。
- 実行ツールまたは範囲チェックは、アプリケーションの整合性と信頼性を監視するために、別のツールとして提供されます。
注: 自動コンパイラーメソッドにより、変数定義用の重要なツールも提供されています。 — 変数定義を生成するを参照してください。
シンボルファイルはテキストタイプのドキュメントであり、その長さはデータベースサイズによって異なります。デフォルトでは、コンパイル時にこのファイルは生成されません。このファイルを生成するには、データベース設定の該当するオプションを選択しなければなりません (コンパイルオプション参照)。このファイルが生成されると、データベースのストラクチャが格納されているフォルダー内に配置され DatabaseName_symbols.txt のような名前が付けられます
テキストエディターでシンボルファイルを開くと、次のように表示されます:
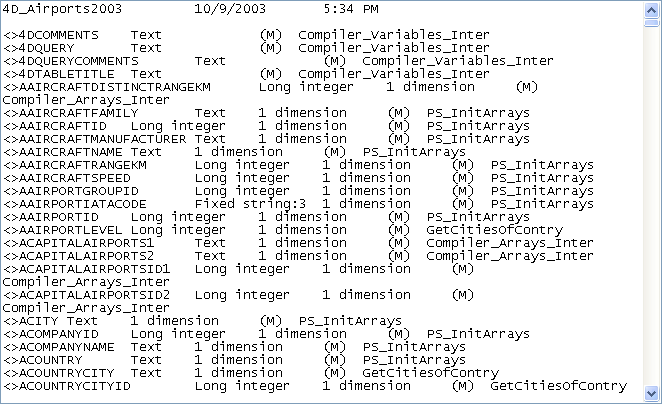
ヘッダーにはデータベースの名前、ドキュメントの作成日付と時刻が表示されます。このドキュメントは4 つの部分に分かれています:
- インタープロセス変数のリスト
- プロセス変数のリスト
- メソッド内のローカル変数のリスト
- プロジェクトメソッドとデータベースメソッドのリスト、およびそのパラメーター(該当する場合)。
これら2 つのリストは、4 つのカラムに分かれています:
- 最初のカラムには、データベースで使用されるプロセス変数、インタープロセス変数、および配列の名前が納められます。変数は文字順に表示されます。
- 2 番目のカラムには、その変数のタイプが納められます。各タイプは、コンパイラー命令コマンドにより設定されるか、または変数の使われ方に基づいてコンパイラーが判断します。変数のタイプが特定できない場合、このカラムは空欄になります。
- 3 番目のカラムには、変数が配列の場合に、その次元数が表示されます。
- 4 番目のカラムには、コンパイラーが変数のタイプを決定したコンテキストへの参照が格納されます。変数が複数のコンテキストで使用されている場合は、コンパイラーが変数タイプを決定する際に使用したコンテキストが表示されます。
- 変数がデータベースメソッド内で検出された場合、(M)* に続けて4D で定義されたデータベースメソッド名が表示されます。
- 変数がプロジェクトメソッド内で検出された場合、(M)に続けて4D で定義されたメソッド名が表示されます。
- 変数がトリガー(テーブルメソッド)内で検出された場合、(TM)に続けてテーブル名が表示されます。
- 変数がフォームメソッド内で検出された場合、テーブル名と(FM)に続けてフォーム名が表示されます。
- 変数がオブジェクトメソッド内で検出された場合、フォーム名、テーブル名、(OM)に続けてオブジェクトメソッド名が表示されます。
- 変数がフォーム上のオブジェクトであり、プロジェクトメソッド、フォームメソッド、オブジェクトメソッド、トリガーのいずれでも使用されていない場合は、(F)に続けてそのオブジェクトが使用されるフォーム名が表示されます。
注: コンパイル時に、コンパイラーは特定のプロセス変数が使用されているプロセスを判別できません。プロセス変数には、各プロセスごとに異なる値が格納されている可能性があります。そのため、新規プロセスが開始されるたびに、すべてのプロセス変数が意図的に複製されます。したがって、メモリ上でこれらのプロセス変数が占める容量に注意することをお勧めします。また、プロセス変数に必要な容量は、プロセスのスタックサイズとは関係ないという点に留意してください。
ローカル変数のリストは、データベースメソッド、プロジェクトメソッド、トリガー(テーブルメソッド)、フォームメソッド、オブジェクトメソッドごとに、4Dと同じ順番で並べ替えられています。
このリストは、3 つのカラムに分かれています:
- 最初のカラムには、メソッドで使用されるローカル変数のリストが納められます。
- 2 番目のカラムには、その変数のタイプが納められます。
- 3 番目のカラムには、変数が配列の場合に、その次元数が表示されます。
- 戻り値の型 (戻り値のあるプロシージャーまたは関数)
- パラメーターの型 (受け渡される引数および戻される値)
- コール数
- スレッドセーフまたはスレッドアンセーフ・プロパティ (プリエンプティブ4Dプロセス 参照)
この情報は、次の形式で示されます:
プロシージャーまたは関数 <メソッド名>(パラメーターのデータタイプ):戻り値のデータタイプ, コール数, スレッドセーフまたはスレッドアンセーフデータベース設定にあるオプションを使用して、コンパイル時にエラーファイルを生成するかどうかを選択することができます (コンパイルオプション参照)。エラーファイルを生成する場合、そのファイルにはDatabaseName_errors.xmlという名前が自動的に付けられ、データベースのストラクチャーファイルと同階層に保存されます。
コンパイラーウインドウからエラーに直接アクセスすることができますが、特にクライアント/サーバー環境で複数の開発者が共に作業を行うような体制であれば、あるマシンから別のマシンへ送信できるエラーファイルがあると便利です。エラーファイルは、その内容を自動的に解析しやすいようにXML フォーマットで生成されます。また、エラー表示用に独自のインターフェースを作成することもできます。
エラーファイルの長さは、コンパイラーにより生成されるエラーと警告の数により変わります。テキストエディターでエラーファイルを開くと、次のように表示されます:
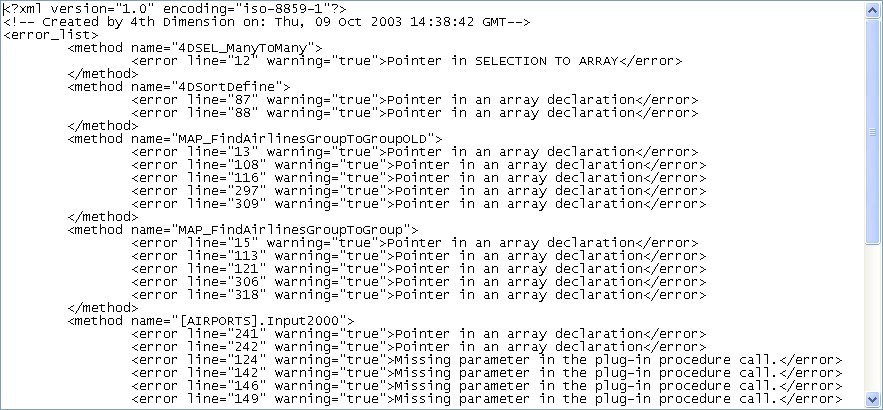
エラーファイルの構造は次の通りです:
- ファイルの一番上にはエラーと警告のリストがあり、メソッドごと、そして4Dで作成された順序で並べられます。
- “*** 全般的なエラー***”セクションには、タイプ定義が行えないものと識別が不明確なものがすべて集められます。これらのエラーと警告は、次の形式で表示されます:
- 1 番目は、メソッドにおける行番号(0 は全般的なエラーを表わす)
- 2 番目の“warning”属性は、検出された異常が警告であるのか(warning="true")、あるいはエラーであるのか(warning="false")を表わす
- 3 番目には、エラーを解説する診断を表示
エラーファイルには、次の3 つのタイプのメッセージが含まれます:
- 特定の行に関連するエラー
- 全般的なエラー
- 警告
これらのエラーは、その説明とともにコンテキスト(エラーが見つかった行)内に表示されます。コンパイラーは、データタイプやシンタックスに関する矛盾を表現式で見つけると、このタイプのエラーをレポートします。
コンパイラーウインドウでは、検出された各エラーをダブルクリックすると、該当するメソッドが直接4D のメソッドエディターで開かれ、エラーを含む行が反転表示されます。
シンタックス/タイプ定義の診断エラーの一覧は、4D ランゲージリファレンスマニュアルのエラーメッセージを参照してください。
これらのエラーは、データベースのコンパイルを不可能にします。コンパイラーが全般的なエラーを生成するケースは、次の2 つです:
- プロセス変数のデータタイプが決定できない。
- 異なる2 つのオブジェクトが同じ名前である。
全般的なエラーは特定のメソッドに関連していないため、このような名前が付けられています。最初のケースの場合、コンパイラーはデータベースのいずれの箇所でも、指定されたタイプ定義を実行できません。2 番目のケースでは、いずれのオブジェクトに特定の名前を割り当てるべきかを決定できません。
全般的なエラーの一覧は4D ランゲージリファレンスマニュアルのエラーメッセージを参照してください。
警告はエラーではありません。警告により、データベースがコンパイルできなくなることはありません。これは、エラーになる可能性のあるコードを示すだけです。
コンパイラーウインドウにおいて、警告はイタリック体で表示されます。それぞれの警告をダブルクリックすると、該当するメソッドが直接4D のメソッドエディターで開かれ、その警告に関係する行が反転表示されます。警告の一覧は4D ランゲージリファレンスマニュアルの警告メッセージを参照してください。
特定の警告を無効にすることができます (コンパイル時に警告を無効にする参照)。
データベース設定において、範囲チェックはデフォルトで選択されています (コンパイルオプション参照)。
他のオプションはすべてコンパイル時に機能しますが、範囲チェックはコンパイル済みデータベースの実行時にチェックを開始します。つまり、範囲チェックのメッセージは、データベースの実行中にのみ表示されます。
範囲チェックは補助的な検証を行い、論理上および構文上の矛盾点を探します。通常、これはコンパイラーの役割です。範囲チェックを行う際に、コンパイラーは“リクエストされた内容を考慮すると、得ようとしている結果は意外なものでしょうか?”という質問を投げかけます。範囲チェックは“現場”のコントローラのようなものであり、一定の時点でデータベース内のオブジェクトのステータスを評価します。
範囲チェックは次のように機能します。例えば、配列MyArrayをテキストとして定義します。MyArrayの要素数は、カレントメソッドに応じて変わるものとします。If you MyArray の5 番目の要素に“Hello”という値を代入したい場合、以下のように記述します:
MyArray{5}:="Hello"この時点で、MyArray に5 つ以上の要素が存在すれば何も問題ありません。代入は正常に行われます。しかし、この時点でMyArray の要素数が5 つ未満であれば、代入は無効になります。
このような状況は、メソッドが実行されることを前提としているため、コンパイル時に検出することができません。コンパイラーは、このメソッドが呼び出される状況は分かりません。データベースの使用時に実際に行われる操作を監視できる方法は、範囲チェックだけです。前述の例題では、コンパイラーは4D を使用して実行時エラーを表示します。配列、ポインター、文字列を処理する場合に、範囲チェックが特に役立つ理由は、すぐにお分かりでしょう。
範囲チェックを要求した場合に、コンパイラーから生成されるメッセージは4Dランゲージリファレンスマニュアルの範囲チェックメッセージに記載されています。
範囲チェックが有効な場合でも、コード内で間違いがないと思われる箇所に対して範囲チェックを適用したくないときもあります。具体的に言うと、かなりの回数繰り返されるループに関し、旧式のマシン上でコンパイル済みデータベースを実行すると、範囲チェックにより処理速度が著しく低下するおそれがあります。関連するコードに誤りがなく、システムエラーを引き起こさないことが確実であれば、範囲チェックをローカル上で無効にすることができます。
これを行うには、範囲チェックから外すコードを特殊なコメントである“`%R-”と“`%R+”で囲みます。//%R- コメントは範囲チェックを無効にし、 //%R+ はそれを再び有効にします:
... //範囲チェックは有効
// %R-
... //ここに範囲チェックから外すコードを記述する
// %R+
... //これ以降のメソッドでは、範囲チェックが再び有効注: このメカニズムは、範囲チェックが有効である場合にのみ機能します。
例えば、データベースの実行中に異常に気付いたものとします。その問題の原因について推測する前に、コンパイラーより提供される手がかりを思い出してください。
考えられる異常としては、次のようなものがあります:
- 4D から独自のエラーメッセージが表示される
可能であれば、4D の指示に従ってデータベース内のエラーを修正します。指示が漠然としすぎている場合は、範囲チェックを必ず指定してデータベースを再度コンパイルします。データベースをテストし直すと、4D メッセージが表示された場所に、より情報量の多いメッセージがコンパイラーから表示されます。 - コンパイル済みデータベースとインタープリター版データベースの動作が一致しない場合
シンタックスチェックの結果生成される警告メッセージを詳しく見てください。 - 数値変数や文字列変数が予期しない値を返す場合
データベース設定にあるデフォルトの変数タイプオプションを確認してシンボルファイルを調べ、すべての変数が適切に型定義されているかどうかをチェックしてください。 - データベースがインタープリターモードでは動作するが、コンパイル済みモードではシステムクラッシュが発生する場合
範囲チェックオプションを使用してデータベースをコンパイルしたかどうかを確認し、コンパイル済みデータベースがコンパイル時に使われたものと同じプラグインを使用しているかどうかを調べます。

プロダクト: 4D
テーマ: コンパイル
変更: 4D v15 R5
%R, warning, Contrôle d'exécution
デザインリファレンス ( 4D v16)
デザインリファレンス ( 4D v16.1)
デザインリファレンス ( 4D v16.3)






