
4D v14
4D Server Architektur
- 4D Server Handbuch
-
- Einleitung
-
- Überblick
- 4D Server Architektur
 4D Server Architektur
4D Server Architektur
Die 4D Server-Architektur ist leistungsstark, weil sich Arbeitsstationen und Server die Arbeit teilen.
Der Server speichert und verwaltet die Daten. Die Arbeitsstationen schicken dem Server Anfragen und erhalten von diesem die Ergebnisse.
Um z.B. nach einer Reihe von Datensätzen zu suchen, sendet die Arbeitsstation eine Suchanfrage an den Server. Der Server führt bei Empfangen der Anfrage die Suchoperation lokal auf dem Server-Rechner aus und sendet nach Beenden der Suche das Ergebnis, d.h. die gefundenen Datensätze an die Arbeitsstation zurück.
Die Architektur von 4D Server basiert auf dem Client/Server Modell. Schon seit vielen Jahren hat sich diese Architektur gegenüber dem alten Gegenspieler, der File Sharing Architektur, durchgesetzt und ist zum effizientesten Modell für Anwendungen im Mehrplatzbetrieb geworden.
4D Server gleicht den Client/Server-Architekturen, die in der Welt der Minicomputer eingesetzt werden. Es gibt jedoch zwei signifikante Unterschiede:
- Die benutzerfreundliche, grafische Oberfläche auf allen Ebenen der Datenbank
- Eine integrierte Architektur, die für gesteigerte Leistung und Geschwindigkeit sorgt.
Vor Einführung der Client-/Server-Architektur verwendeten Systeme im Mehrplatzbetrieb das File Sharing Modell der Netzwerk-Architektur. In diesem Modell nutzen alle Benutzer denselben Datenbestand, die Daten werden jedoch nicht über eine zentrale Datenbank-Engine verwaltet. Jede Arbeitsstation muss eine Kopie der Datenbankstruktur und -Engine speichern, während der Server nur die Software steuert, die zum gemeinsamen Nutzen der Dateien auf dem Netzwerk erforderlich ist.
Im File Sharing Modell führt jede Arbeitsstation alle Änderungen an den Daten lokal aus. Das führt zu massivem Datenverkehr im Netz, da jede Anfrage aus unzähligen Netzwerkübertragungen besteht. Folgendes Beispiel zeigt den Datenverkehr im Netz, wenn ein Benutzer in der Datenbank nach allen Personen mit dem Nachnamen Müller sucht:
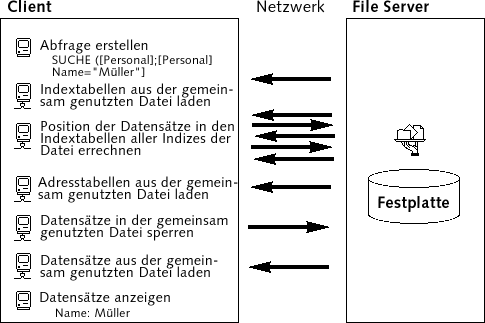
Ein weiterer Nachteil ist, dass die Daten nicht in einem gemeinsamen Cache-Speicher abgelegt werden können, denn dann könnten vom gleichen Datensatz verschiedene Versionen existieren, was zu Dateninkonsistenz führen würde. Da jede Station einen eigenen Cache-Speicher verwendet, wissen die Stationen nicht, welcher Teil des Datensatzes sich gerade bei einer Station befindet. Der Server bleibt passiv, d.h., er speichert die Daten, anstatt sie aktiv zu verwalten. Er unterstützt die Benutzer nicht. Sie müssen selbst die Daten heranholen und auf der Station bearbeiten. Von daher herrscht im Netz ein ständiger Datenverkehr.
In der Welt der Minicomputer ist die Client/Server Architektur wegen ihrer Leistungsstärke und Geschwindigkeit für umfangreiche Datenbanksysteme weit verbreitet. In dieser Architektur ist die Arbeit zwischen dem Server-Rechner und den Clients aufgeteilt, was die Performance entscheidend verbessert.
Der Server enthält die zentrale Datenbank-Engine, welche die Daten speichert und verwaltet. Die Engine ist die einzige Software, die auf die Daten zugreift, die auf der Festplatte gespeichert sind. Sendet ein Client eine Anfrage an den Server, sendet der Server das Ergebnis zurück. Das kann ein spezifischer Datensatz sein, den der Client ändert oder eine sortierte Liste von Datensätzen.
Im allgemeinen werden die meisten Client/Server Architekturen auch heterogene Architekturen genannt, da die Front-end Anwendungen, die auf den Client-Rechnern laufen und die Datenbank-Engine, die auf dem Server-Rechner läuft, zwei vollkommen unabhängige Einheiten sind. Sie brauchen daher einen Datenbank-Treiber, der als Übersetzer zwischen Arbeitsstation und Server dient.
Um beispielsweise nach einem Datensatz zu suchen, sendet der Client eine Anfrage an den Server. Da die Datenbank auf dem Server liegt, führt der Server den Befehl lokal auf dem Server-Rechner aus und sendet das Ergebnis an den Client-Rechner. Folgende Abbildung zeigt den Datenverkehr im Netz, wenn ein Benutzer den Server beauftragt, nach allen Personen mit dem Nachnamen Müller zu suchen und anschließend die Datensätze anzuzeigen:
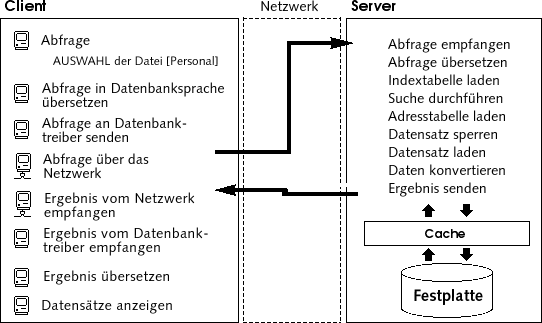
Dieses Beispiel zeigt zwei entscheidende Unterschiede zwischen File Sharing und dem Client/Server Betrieb:
- Die Client/Server Architektur arbeitet mit Cache-Speicher: Da nur die Engine real auf die Daten zugreift, kann der Server einen Cache-Speicher betreiben, der geänderte Datensätze speichert, bis sie auf die Festplatte geschrieben werden. Die Daten werden von einer zentralen Stelle gesendet, so dass die Arbeitsstationen immer die aktuellste Version des Datensatzes empfangen. So ist die Datenintegrität gewährleistet. Darüberhinaus werden Operationen in der Datenbank durch Verwendung des Cache-Speichers beschleunigt, da der Zugriff nicht über die Festplatte, sondern über den Cache läuft. In File Sharing Architekturen wird immer auf die Festplatte zugegriffen.
- Datenbankoperationen im Hintergrund laufen auf dem Server ab: Die Client/Server Architektur bietet deutlich höhere Geschwindigkeit, da Datenbankoperationen, wie Erstellen eines Index oder Sortieren von Tabellen, auf dem Server Rechner mit dessen Rechnergeschwindigkeit ausgeführt werden. In File Sharing Architekturen laufen die gleichen Operationen durch Netzwerkübertragungen und Grenzen der Arbeitsstation viel langsamer ab.
Bei herkömmlichen Client/Server-Architekturen besitzt der Server keine Informationen über die Umgebung der Arbeitsstation. Die Daten vom Server sind Rohdaten, die die Arbeitsstation interpretiert, z.B. mit übergebenen Arrays.
Bei 4D Server arbeiten Server und Arbeitsstation mit derselben Datenstruktur. Die Daten, die beide ans Netz senden, sind bereits strukturiert. Das heißt, Arbeitsstation und Server können sie direkt lesen.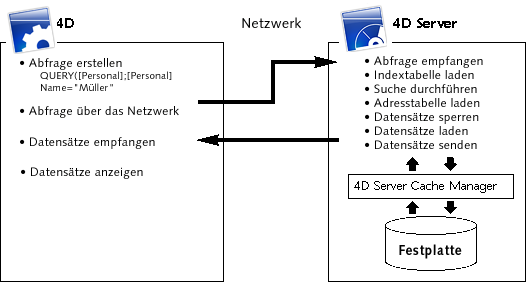
Die Arbeitsstation ist zuständig für:
- Anfragen: Der Client sendet Anfragen an den 4D Server. Sie können Anfragen über die integrierten Such- und Sortiereditoren erstellen, per Programmierung oder via SQL. 4D bietet Editoren zum Erstellen und Ändern von Methoden und verwaltet Variablen und Arrays.
- Antworten: Der Client empfängt Antworten vom 4D Server und aktualisiert die Daten auf der Arbeitsstation. Fragt der Client z.B. nach allen Datensätzen mit dem Nachnamen "Müller", erhält er diese Datensätze vom Server und zeigt sie in einem Formular an.
Der Server ist zuständig für:
- Zugriffe: 4D Server verwaltet über Multitasking konkurrierende Zugriffe und alle Prozesse, die von Clients erzeugt werden.
- Struktur und Datenobjekte: 4D Server speichert und verwaltet sämtliche Objekte der Datenbank, d.h. Daten (Datensätze, aktuelle Auswahl) bzw. Strukturobjekte (Tabellen, Datenfelder, Formulare, Methoden und Menüs).
- Cache: 4D Server unterhält einen Cache, der Datensätze sowie spezifische Datenobjekte enthält, wie z.B. Auswahlen und Mengen einzelner Clients.
- Low-level Datenbankoperationen: 4D Server führt Datenbankoperationen, wie Such- und Sortierläufe nach indizierten Datensätzen aus.
Beispiel:
Die Arbeitsstation fragt beim Server ein Formular ab. Ein umfangreiches Formular braucht eine bestimmte Zeit im Netz. Der Server schickt das Formular an die Arbeitsstation. Dort wird es ohne weitere Arbeit für den Server selbständig bearbeitet. Dadurch reduziert sich die Serveraktivität erheblich. So ist die Auslastungsrate des Servers für 10 Stationen, die gleichzeitig im Benutzer- und Änderungsmodus in 10 verschiedenen Formularen mit jeder Menge Bilder arbeiten, relativ gering.
Die gegenseitige Verständigung zwischen Server und Arbeitsstation ist besonders vorteilhaft beim Anzeigen von Listen und Verwalten der aktuellen Auswahl.
Der Server schickt mehrere Datensätze als Paket an die Arbeitsstation. Dieses enthält im Gegensatz zu einer herkömmlichen, heterogenen Client/Server-Architektur keinen Code. Die Arbeitsstation kann selbst die Daten zerlegen. Die Anzeigeschnittstelle wird automatisch verwaltet. Da die Engine der Arbeitsstation mit dem Server kommunizieren kann, überträgt die Arbeitsstation nur die tatsächlich benutzten Datenfelder.
Die Arbeitsteilung zwischen Arbeitsstation und Server ist eindeutig festgelegt. Sie erfolgt automatisch durch 4D. Sie benötigen dafür keine besonderen Kenntnisse. Sie kann vielmehr zu neuen Strategien für Ihre Anwendungen beitragen.
Produkt: 4D
Thema: Einleitung
4D Server Handbuch ( 4D v13)
4D Server Handbuch ( 4D Server v12)
4D Server Handbuch ( 4D Server v11 SQL Release 6)
4D Server Handbuch ( 4D v14 R2)
4D Server Handbuch ( 4D v14)
4D Server Handbuch ( 4D v14 R3)
4D Server Handbuch ( 4D Server v14 R4)





